Automatic Data Extraction
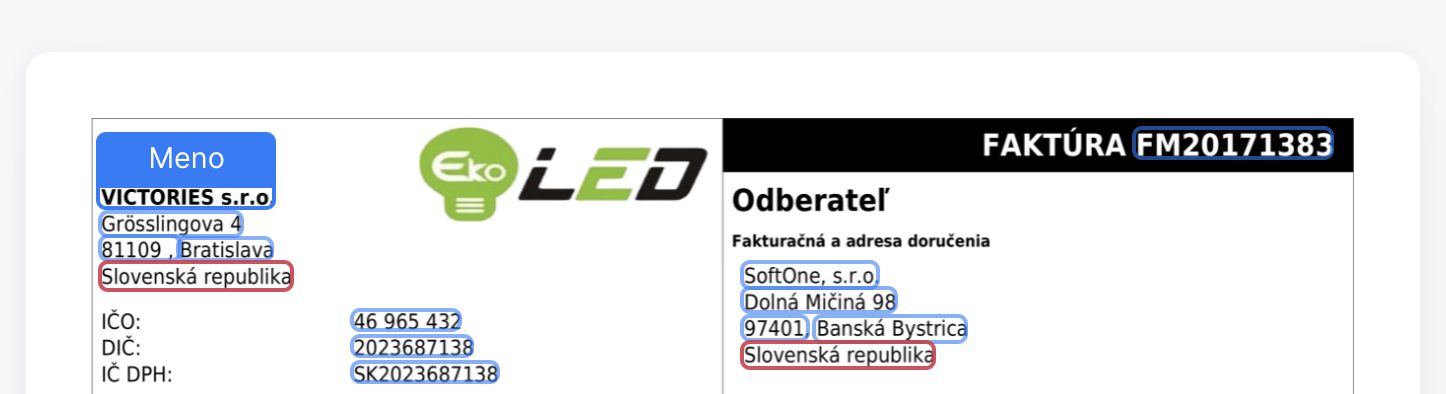
Invoice data extraction is a process that allows data from a document (invoice) to be automatically transferred into your accounting software through specialized software. This software, utilizing artificial intelligence and other modern technologies, can recognize necessary data in the document, such as invoice number, business partner name, dates, amounts, variable symbol, payment account, invoiced items, and more. It doesn’t matter if the invoice is in electronic form (e.g., PDF, JPG) or paper form.
Main Benefits:
- Significant time savings with faster data processing,
- cost savings by replacing human work with automation, and
- reducing errors in data transcription.
Workflow
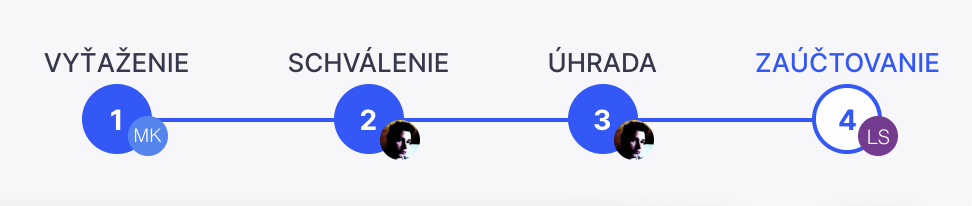
A workflow can be understood as a sequence of steps where documents or tasks are transferred from one participant to another for further processing. Practical applications of workflow can be seen in business process automation, such as implementing approval processes within company documents. A properly set workflow can streamline and expedite individual tasks, making the entire process more transparent and faster. Workflow represents the automation of a business process, allowing documents, information, and tasks to be passed from one participant to another according to predefined rules.
Quick Search
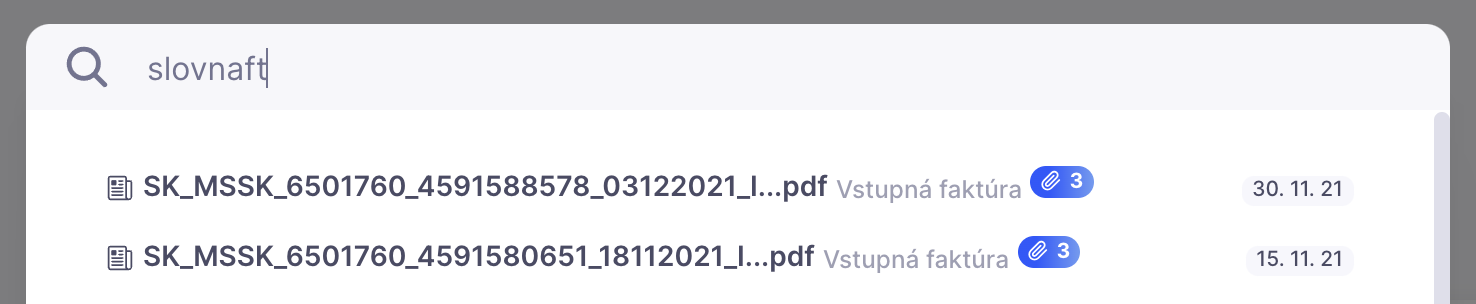
No more lengthy searches through drawers, binders, or archives. No more flipping through hundreds of pages to find hidden information. A digital archive provides quick search functionality. Just type in one or two words, and the system instantly presents documents containing those terms, regardless of whether they were processed yesterday or added ten years ago.
Discussions
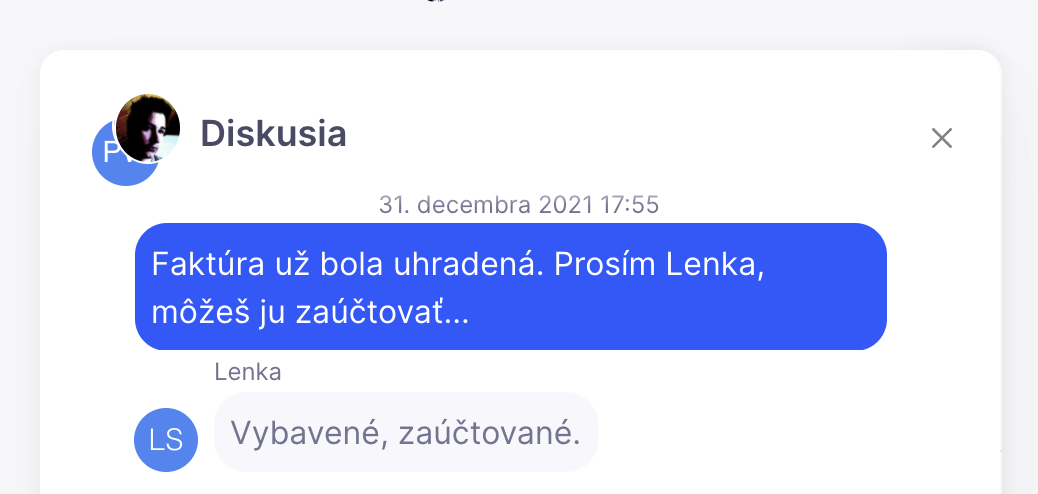
Sometimes, you need to ask a colleague about a specific data point, payment account, or which accounting category to use. You can add any questions or notes directly to the document using the discussion feature. Colleagues will be notified and can respond, and the entire discussion remains a part of the document for its entire archival period.
Online Archive
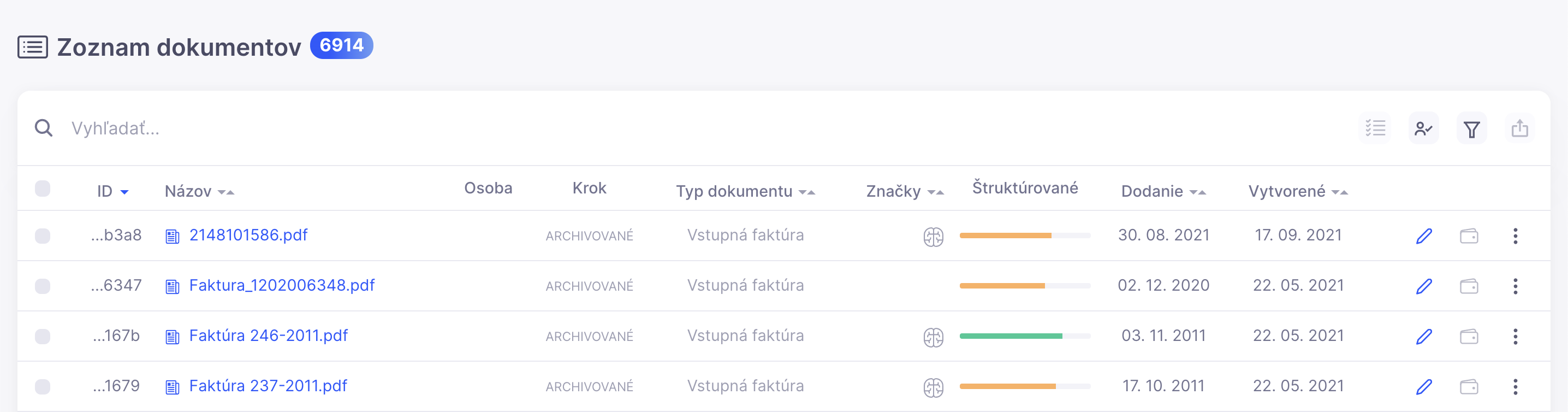
Every document uploaded to the DocFlow system is immediately archived. Text within it is digitized, and key data is automatically extracted using artificial intelligence. This allows you to quickly and easily search for required information anytime, even 20 years later. Fast, organized, and accessible from anywhere on your computer, tablet, or phone. Your data is automatically backed up, eliminating the risk of data loss. If needed, they can also be backed up in another location via FTP or downloaded as a ZIP archive.
Detailed Filters

The DocFlow system allows for detailed filtering options. You can, for instance, search for specific document types or invoices that are yet to be paid. You can search for documents within a selected tax period, overdue documents, or documents assigned to a specific person or in a particular workflow step. Additionally, you can filter by custom tags or extracted data.
Explanation of the Learning Process
Preparation
The primary and only resource for artificial intelligence (hereinafter AI) is data. The more data, the better. The first task, therefore, is to gather as many documents (data) as possible for the AI to learn from. For the following step, training, we need to reach at least a certain document count, say 100. Ideally, this would be 100 unique documents of the same type – for example, 100 invoices.

Training
Once we reach the basic document count, training begins. Training consists of numerous learning cycles. In each cycle, the system takes our data sample and performs learning on it using initial parameters (weights). After each learning cycle, it calculates the learning success rate and mathematically adjusts the parameters (weights) to perform better in the next cycle. In the following cycle, it repeats learning with these new parameters and assesses its learning success. If the success rate is higher, it continues fine-tuning the parameters. If the success rate is lower, it reverts to the previous parameter settings and tries adjusting different weights. This cycle-based learning repeats many times until it reaches a point where further parameter adjustments yield almost no improvement.
At this point, the training concludes, and the final parameter settings are saved as an output – a model. The DocFlow.ai system then uses this model for automatic data extraction from your documents.
Automatic Learning
The DocFlow.ai system is designed to learn from various types of documents. As we work with various document types in everyday practice (invoice, receipt, order, contract, etc.), we need to search for different types of information in each type. For instance, in an invoice, we look for information about the recipient's/supplier's address, billing details (company name, ID number, tax ID, etc.), payment information (IBAN, reference number, amount), and details about invoiced items and VAT. On a contract, we only look for party A, party B, and the contract number.
Therefore, the primary parameter for each document is its type. For each type, the DocFlow.ai system learns to predict the required information. Whenever you add and complete, say, 10 new documents, the system retrains itself. This is how the continuous learning process on your documents functions. With each additional document, the prediction accuracy will improve, and your model will become more effective.
The DocFlow.ai system also works so that if a model has not yet been trained for your documents due to a small number of documents (for example, if you just started using the system but have fewer than 100 completed documents), it automatically offers you the option to use a universal pre-trained model. This model has been trained on 5,000 invoices processed by us. Thus, DocFlow.ai helps with automatic data extraction immediately after registration, so you don’t have to wait for the model retraining after the first 100 documents.
Utilize artificial intelligence in your business?
Contact us, and we’ll help you optimize your business using AI.